 Traditional Chinese
Traditional Chinese Register
RegisterChatGPT API cost analysis: Which model is best for your application?

With the widespread application of generative AI technology, more and more developers and companies rely on OpenAI API to build smart applications. However, the fee structures of various models vary, and choosing the right plan and managing costs effectively has become a major challenge. In this article, we’ll take a deep dive into the ChatGPT API fee structure and share practical cost optimization strategies to help you use it efficiently.
ChatGPT API fee structure and model explained
OpenAI API FeesIt is calculated based on the selected model. Newer models include:
- GPT-4o:Current ChatGPTFlagship Model, suitable for applications that respond to various scenarios and need to control costs. The price of each million input tokens is $2.5 USD.The output token is $10 USD.
- GPT-4o Mini:This modelSignificantly lower costs and very fast, ideal for cost-sensitive applications. The price is only $0.15 per million input tokens and $0.6 per million output tokens. This model is ideal for early development stages and small to medium-sized applications, and is suitable for simple content generation tasks.
- o1: This model is the latest version from OpenAI.Good at reasoning about complex, multi-step tasksModel. The input price is about $15 per million tokens, and the output price is $60 per million tokens. The model thinks before answering, generating a long internal chain of thoughts before responding to the user.
- o1-mini:This is a simplified version of o1-preview.Fast reasoning models for special tasks, the cost is more economical. The price per million input tokens is about $3 USD, and the fee per million output tokens is $12 USD.
| Model (USD/million tokens) | enter | Input(Cache) | Output |
|---|---|---|---|
| GPT-4o | $2.5 | $1.25 | $10 |
| GPT-4o mini | $0.15 | $0.075 | $0.6 |
| o1 | $15 | $7.5 | $60 |
| o1-mini | $3 | $1.5 | $12 |
ChatGPT API Token Pricing Model
ChatGPT APIuseToken Billing Model, token is the smallest unit of language processing in the system. Whenever you send a request, whether it is an input or an output, the system will be billed based on the number of tokens. Therefore, in order to effectively control the total cost, you can reduce token consumption by streamlining input content and controlling output length.
OpenAI provides a tool that can help you estimate token usage.OpenAI TokenizerUse on. Generally speaking, a token corresponds to approximately 4 English letters or 3/4 words, which means that 100 tokens are approximately equal to 75 words. However, different models may have slight differences in token calculation.
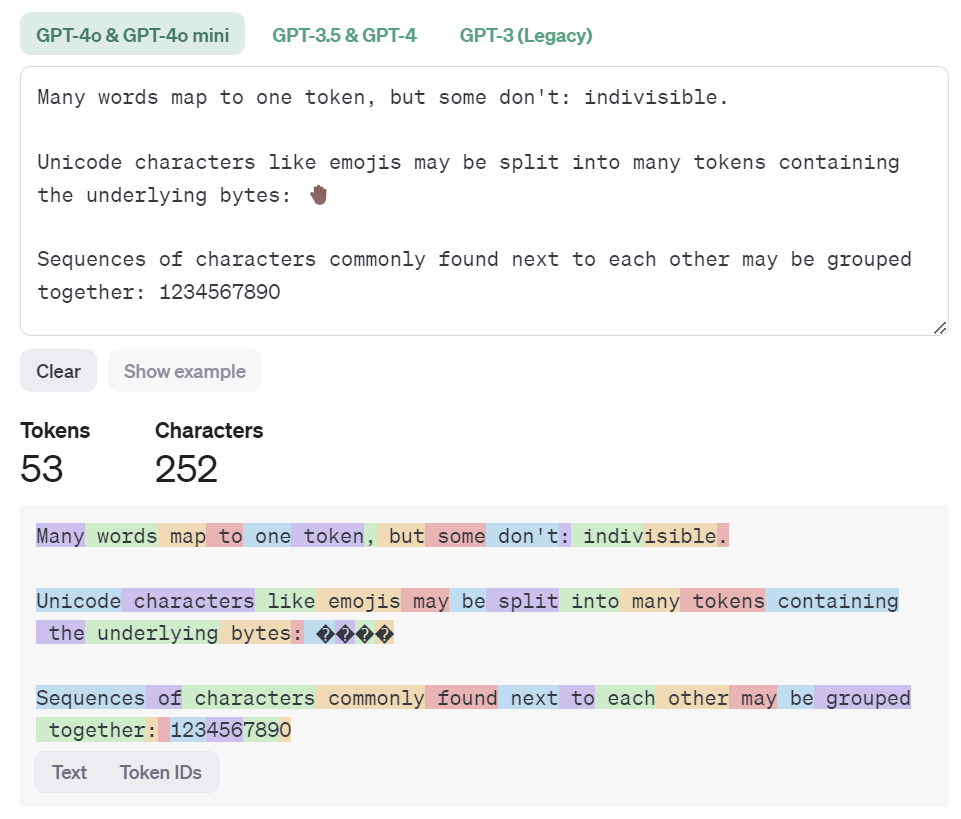
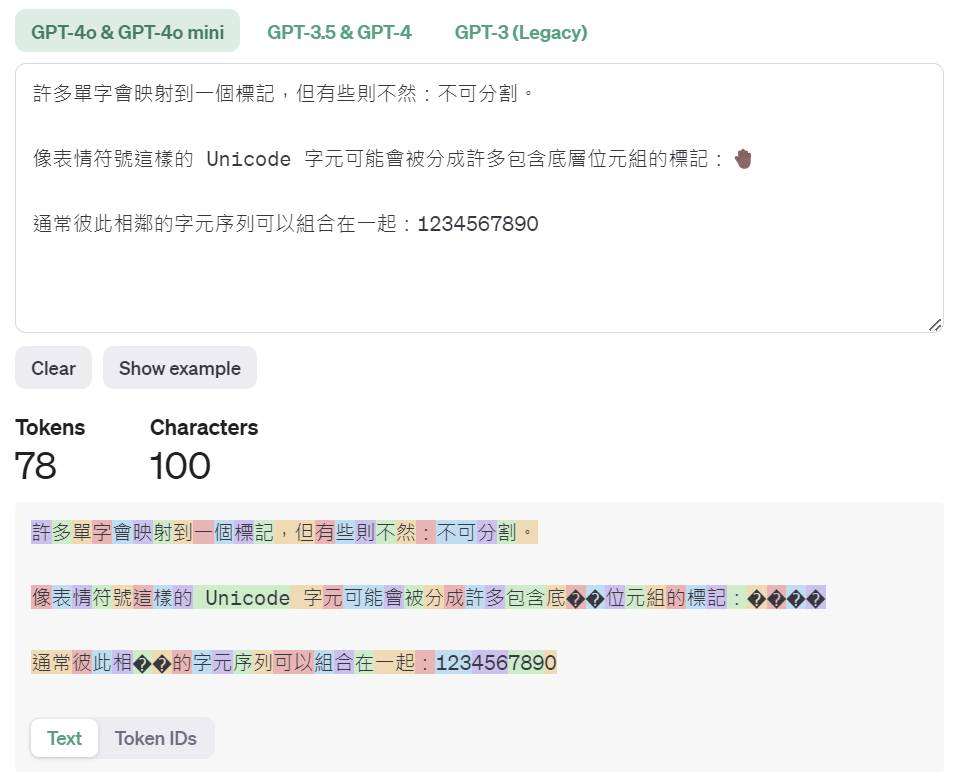
It should be noted that when usingWhen using Traditional Chinese, token consumption is usually higher than English. Due to the high character density of Chinese, text of the same length may consume more tokens. Taking the translation of OpenAI's official examples as an example, after the Chinese translation, the number of tokens is 78, which is 47% more than the 53 tokens in the English content.
How to choose the right model?
The GPT-4o series is ideal for scenarios requiring a broad knowledge base and diverse applications. The model excels in language generation and common sense application, and is particularly suitable for tasks such as text creation and language processing. As an economical choice, GPT-4o Mini can still handle application scenarios that do not require highly complex reasoning at a lower cost and provide stable performance.
In contrast, the o1 series focuses more on reasoning skills and complex problem solving, and excels in STEM fields such as science, mathematics, and programming. Among them, o1 is the most powerful model in the series. It can handle difficult mathematical calculations and programming tasks and has strong reasoning capabilities, but its cost is relatively high. The o1-mini is a more cost-effective option optimized for STEM fields, providing inference performance close to that of the o1, but with lower operating costs. In scenarios such as math competitions and programming challenges, o1-mini performs well and can quickly solve problems, making it an ideal choice for efficient reasoning needs.
If you want to know how to connect to ChatGPT API, you can refer toQuick Start: How to easily connect to the ChatGPT API?
API cost optimization strategy
The key to properly managing costs when using the ChatGPT API is to accurately assess your model requirements. Different models have their own characteristics and cost structures. For example, o1-mini may even surpass the performance of o1 under targeted training. As the saying goes, it’s better to use a sledgehammer to crack a nut. Choosing the right model can significantly reduce operating costs. In applications, the model can be flexibly adjusted according to the complexity of different tasks. For example, low-cost models can be used for tasks that do not require high language generation, while high-performance models can be reserved for more critical computing scenarios.
Specific cost control strategies include the following:
- Optimize request content:Reduce unnecessary input and output tokens, streamline request content, and limit response length, thereby reducing the cost of a single API request.
- Choosing the right model: Choose a low-cost model such as o1-mini or GPT-4o Mini based on your needs to balance performance and cost-effectiveness.
- Reasonable planning of usage: Before large-scale deployment, predict the usage of API tokens, formulate reasonable usage frequency and plan, and avoid costs exceeding the budget.
Little Pig TechAI Model Integration APIFunction provides users with greater flexibility, weIntegrate APIs from multiple vendors into a unified platform, so that users canFreely choose the most suitable model and service according to specific needs, to achieve efficient cost management. For example, in an application of short video recommendations, the lowest-cost model can be used in the front end to screen preliminary results, followed by further adjustments using the second-best model, and finally accurate recommendations using a high-performance model. This layer-by-layer screening strategy not only optimizes resource utilization, but also significantly reduces computing costs.
in conclusion
The popularity of generative AI technology has made model selection and cost management core challenges for developers. Selecting the right model based on application requirements, such as the GPT-4o series for a wide range of applications, the o1 series focused on complex reasoning, and the o1-mini and GPT-4o Mini providing cost-effective options, is a key strategy to reduce costs.
By streamlining request content, rationally planning usage, and integrating the flexible tools of Xiaozhu Technology's API platform, users can select models on demand and effectively reduce computing costs. For example, in short video recommendations, the application of layer-by-layer screening strategies from low-cost to high-performance models greatly improves efficiency and saves resources. Properly managing the use of generative AI can achieve the optimal balance between performance and cost.
Little Pig Tech's AI model integration API is an ideal solution for enterprises to achieve efficient application and cost optimization. Our platform integrates APIs from many mainstream manufacturers (such as OpenAI, Anthropic, etc.), allowing users to flexibly choose the most suitable model according to their needs and seamlessly apply it to different scenarios.
Our platform supports the integration of multiple mainstream cloud services (such as AWS, Google Cloud, Alibaba Cloud, etc.) to achieve intelligent deployment and automated operations. Whether it is improving IT infrastructure efficiency, optimizing costs, or accelerating business innovation, Littlepig Tech can provide professional support to help you easily cope with the challenges of multi-cloud environments. Please contact our team of experts and we will be happy to assist you. You can alwaysEmail We, private message TelegramorWhatsApp Contact us to discuss how we can support your needs.
search
Classification
Label
- AI API
- AI implementation
- AWS
- CentOS
- ChatGPT
- Claude
- Debian
- DNS Acceleration
- GCP
- Gemini
- Gmail
- Google Calendar
- Google Drive
- Google Meet
- Google Workspace
- Linux
- Llama
- Server
- SSL Certificates
- Ubuntu
- VPS
- Windows
- Invoice issuance
- Team Collaboration Tools
- Domain Transfer
- Multi-cloud management
- Best Hosting for Small Business
- Digital Transformation
- Cost saving
- Domain name
- Domain Registration
- Web Hosting Comparison
- Virtual Server
- Passive Income
- Cloud Server
- Cloud Hosting
- Cloud Server
- Cloud deployment
- High commission
